- はじめに
- 参考
- Satya Nadella 氏の記事を読んでの私の考え要約
- 1. 生成AI 導入の本質は「学習する組織」への変革である
- 2. 人の能力と AI 資産は、相互に強化される
- 3. 人の役割は、実行から委任・評価・統合へ移行する
- 4. 全社統制と現場の自律を両立する組織構造
- 5. Microsoft 365 Copilot エコシステムは管理モデルで使い分ける
- 6. AI 資産は段階的に育て、組織標準へ昇格させる
- 7. 実践からナレッジを生み、次の仕事へ戻す
- 8. セキュリティとガバナンスは継続的に更新する
- 9. 役割、評価、教育、コミュニティ、コストを一体で設計する
- 10. 小さく始め、学びながら継続的に拡大する
- まとめ
- おわりに
はじめに
お久しぶりです。
ブログをかくのはだいぶ久しぶりですね。
ただ、今回の記事は技術的な内容ではなく、この生成AI 時代に 個人/組織 としてどのように向き合うと良いか?という観点をベースに私の考えをざっくりまとめたものになります。
生成AI と広くいっていますが、Microsoft 365 Copilot や Copilot Studio の機能を活用する。という前提条件のもとまとめています。風呂敷広げ過ぎても収集つかないですからね。
まだまだ私の考えも粗が多いので、皆さんの意見も聴けるといいな。と思っています。
情報のまとめには Copilot を活用しています。
内容は私のほうで確認したものを記載していますが、言い回し気になってもそこは読み飛ばして貰えると助かります。
参考
ベースとして Satya Nadella 氏のこちらのノートを参考にさせてもらっています。
特に直近2つの投稿ですね。
まだ見てない方は翻訳して是非読んでみることをおすすめします。
これは私個人が感じた感想でもありますが、読む際の注意点として、こちらは恐らく「生成AI」という全般的な内容について触れており、自社の製品についてなにかしら焦点を置いた記事ではない。ということを念頭に置いて読んだ方が良いんじゃないかな?と思っています。
Satya Nadella 氏の記事を読んでの私の考え要約
Microsoft 365 Copilot/Copilot Studio を起点に考える、個人と組織の将来像
生成AI の導入は、単なる業務効率化ではありません。
文章作成、要約、検索、分析といった個々の作業を速くするだけであれば、その効果は限定的であり、利用する製品やモデルが変わるたびに価値も揺らぎやすいです。
より重要なのは、生成AIを使う過程で生まれる指示、修正、評価、判断、成功・失敗の履歴を、組織固有の能力として蓄積し、次の仕事へ再利用できる状態をつくることであると考えています。
Microsoft 365 Copilot、Agent Builder、Copilot Cowork、Copilot Studioは、そのための具体的な実装基盤となります。
しかし、製品を導入しただけで組織が学習できるようになるわけではありません。
人とAIの役割、業務プロセス、ナレッジ管理、評価、教育、ガバナンス、コスト管理を一体として再設計して初めて、生成AI は組織能力へ変わると考えています。
1. 生成AI 導入の本質は「学習する組織」への変革である
生成AI の導入を、チャットツールの配布や文書作成時間の短縮だけで捉えると、その価値を過小評価することになってしまいます。
生成AI は、利用者の指示、判断、修正、例外対応を通じて、これまで個人の経験や会話の中に埋もれていた学びを記録し、整理し、再利用できる技術です。
そのため、再設計すべき対象は AI の使い方だけではありません。
- 人と AI の役割分担
- 業務プロセス
- 意思決定と説明責任
- 組織構造
- 人材育成
- 評価制度
- ナレッジ管理
- セキュリティ
- コスト管理
これらを個別に扱うのではなく、一つの組織システムとして見直す必要があります。
目指すべき状態は、単に「AI を利用できる組織」ではありません。
AIを前提として仕事を継続的に再設計し、人とAIが生み出す学びを、自社の能力として蓄積・再利用できる組織
です。
組織の競争力は、どのモデルや製品を採用したかだけでは決まりません。
利用結果からどれだけ学び、その学びを次の業務へ戻せるかによって決まります。

2. 人の能力と AI 資産は、相互に強化される
生成AI 時代に重要なのは、人の能力と AI の能力を対立させないことです。
人の専門性、経験、判断力、顧客理解、関係性、暗黙知は、組織の人的資本です。
一方で、AI への指示、エージェント、Skills、評価基準、業務フロー、成功・失敗の履歴、修正内容、ナレッジは、組織が構築する AI 資産となります。
AI 資産が増えることで、人の価値が下がるわけではありません。
人がより高い目標を設定し、異なる領域をつなぎ、結果を評価し、重要な判断を行うことで、AI 資産の品質も高まります。
反対に、蓄積された AI 資産が調査、整理、初稿作成、反復処理を支援することで、人は顧客理解、創造、対話、意思決定といった高付加価値な領域へ集中できます。
このように、人がより高付加価値なコア業務に集中できる状態こそが生成AI 導入により目指す姿だと私は考えています。
この循環を成立させるためには、次の情報を組織の学習資産として保持する必要があります。
- AIへ何を意図して依頼したか
- どの情報やツールを利用したか
- 人がどこを修正したか
- 何を良い成果と評価したか
- どの判断を採用し、どの判断を棄却したか
- どの条件で成功し、どの条件で失敗したか
- 次回どのように改善するか
これらを外部サービスや個人のチャット履歴だけに閉じ込めると、AI を使うたびに学びは生まれていても、その学びを自社の競争力として再利用できません。
生成AI 時代に守るべき資産は、データだけではありません。
評価、修正、判断、成功・失敗、ナレッジ更新の仕組みまで含めて、組織固有の知的資産として管理する必要があります。

3. 人の役割は、実行から委任・評価・統合へ移行する
生成AI 活用が成熟するほど、多くの知識労働者は、すべての成果物を自ら直接作る働き方から、AI や他者へ仕事を委任し、その結果を評価・統合する働き方へ移行していきます。
この役割を私は、AI PM あるいは AI オーケストレーターと表現しています。
ここでいう AI PM は、管理職やプロジェクトマネージャーという職種名ではありません。
自分の仕事を進める際にも必要となる実務能力です。
具体的には、次の能力が求められます。
- 仕事の目的を定義する
- 目的から逆算してタスクを分解する
- 人、Copilot、Cowork、Skills、Agent、Power Automate などを利用した自動化へ適切に委任する
- 利用可能な情報、制約、禁止事項を明示する
- 完了条件と評価基準を定義する
- 複数の案や結果を比較する
- 根拠、欠落、矛盾、リスクを確認する
- 結果を統合し、正式な成果物へ変える
- 最終的な判断と説明責任を担う
- 成功・失敗から得た学びを次回へ残す
これは、単にプロンプトの書き方が上手くなることではありません。
仕事そのものを分解し、人と AI の強みを組み合わせ、最終的な品質と責任を管理する力です。
ただし、全員が Agent Builder や Copilot Studio の開発者になる必要はありません。
全員に必要なのは、AI へ任せる仕事と、人が責任を持つ判断を切り分ける力です。
Agent や Skills を作る役割、Copilot Studio で組織エージェントを設計する役割、全体の標準やガバナンスを設計する役割は、専門性や職務に応じて一部の人材が担うことでも十分組織は回ると思います。
全員にこれらのスキルをすべて身に着けさせようとするのは、教育コストの観点からも好ましくないと思います。

4. 全社統制と現場の自律を両立する組織構造
中規模以上の組織で生成AI を展開する場合、中央組織がすべてを作成・承認する中央集権型では、AI CoE や IT部門がボトルネックになってしまいます。
一方で、各部門へ完全に任せると、重複開発、品質差、所有者不在、セキュリティリスク、コスト増加などの問題が起こってしまいます。
そのため、全社共通の戦略、基盤、ガードレールを AI CoE などの中央部隊が整備し、現場が業務に近い場所で実験・改善するフェデレーテッド型の組織が適していると思います。
中央部隊は、次の役割を担います。
- 経営方針と投資の優先順位
- AI CoE による共通原則、標準、参照アーキテクチャ
- IT・セキュリティによる環境、権限、接続、監査
- 評価基準、リスク分類、公開・廃止ルール
- 共通テンプレート、共通 AI 資産、ナレッジ基盤
- コスト、ライセンス、利用状況の可視化
- 教育、チャンピオン制度、コミュニティ支援
現場側は、次の役割を担います。
- 業務課題の発見
- 小規模な試行と検証
- 業務固有のナレッジや例外の整理
- AI 資産の改善
- 成功・失敗事例の共有
- 業務成果の評価
- CoE へのフィードバック
AI CoE は、何でも作る中央開発部門ではありません。
全社共通の方向性を示し、現場が安全に実験できる土台を提供し、部門を越えて再利用できる資産を選定・標準化する役割を担います。
中央が方向性とガードレールを持ち、現場が実験・改善を担うことで、統制とスピードを両立できるようにします。

5. Microsoft 365 Copilot エコシステムは管理モデルで使い分ける
Microsoft 365 Copilot、Agent Builder、Copilot Cowork、Copilot Studio は、機能・技術として単純な上位・下位の関係ではありません。
誰が利用し、誰が所有し、どのように共有・更新し、どこまで継続保守するかが異なる実行・管理モデルです。
Microsoft 365 Copilot
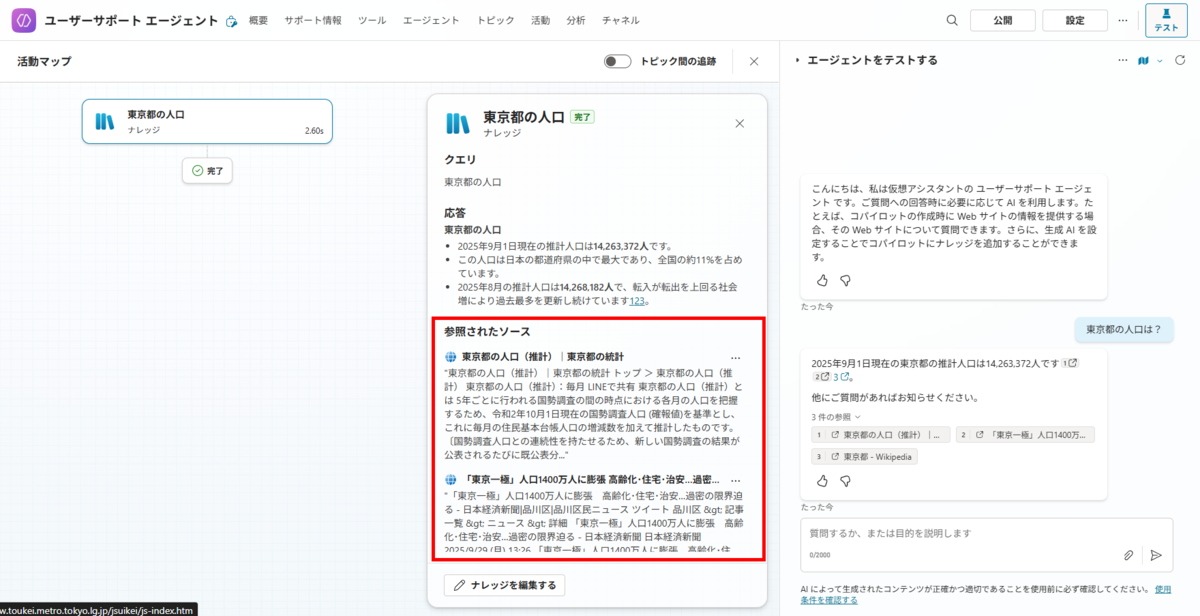
Microsoft 365 Copilot は、個人を主な操作主体とし、Copilot Chat、Excel、Word、PowerPoint、Outlook、Teams などの日常業務で、検索、要約、下書き、分析、会議支援を行う基盤です。
個人の生産性向上を中心とするが、組織のデータ、権限、業務文脈の中で利用されるため、完全に個人だけに閉じた仕組みではありません。
少々乱暴に定義すると、Work IQ のことですね。
Agent Builder
Agent Builder は、個人が短期間でカスタムエージェントを作成し、限定的に共有する用途に適しています。
共有を「限定的」としている理由としては、共有先へ共同編集権限を付与できず、通常の保守が単一所有者へ依存してしまうからです。
管理者による所有権の再割り当ては可能でも、継続的な共同保守、開発・検証・本番の分離、ALM などには向いていません。
したがって、個人利用、短期プロジェクト、検証、使い捨てエージェントには適しますが、異動・退職後も維持する重要な組織エージェントには原則として利用しないほうがよいです。
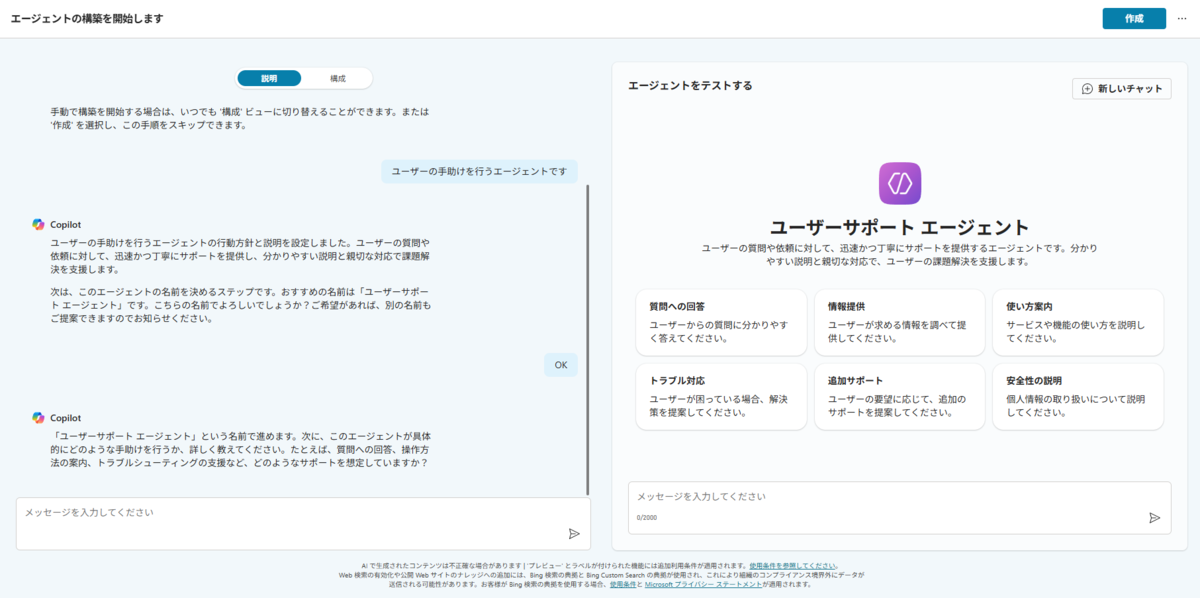
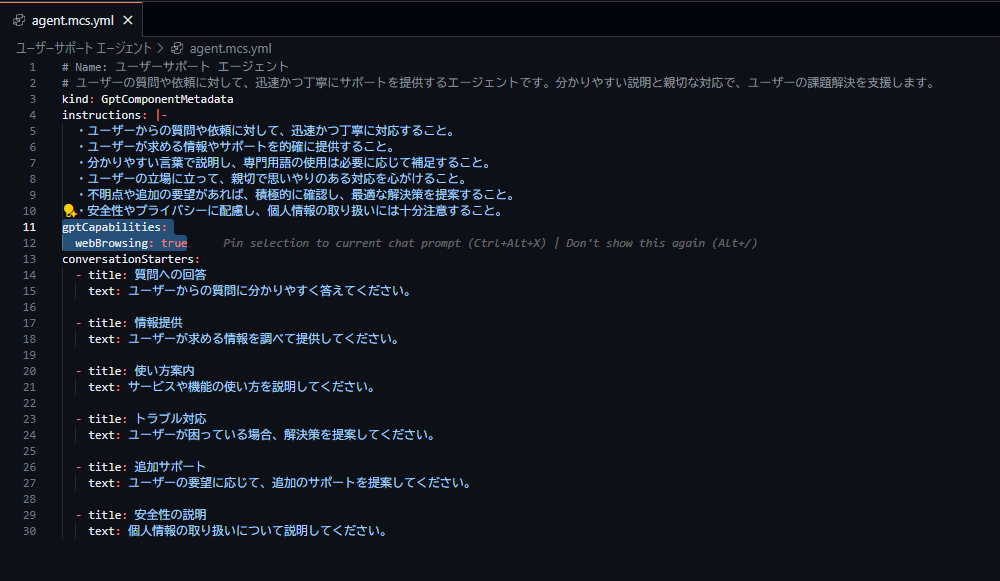
1点留意しておきたい点として、現状 Teams の特定のチャットや会議をナレッジとして Agent を作成したい場合は Copilot Studio では行えず、Agent Builder を利用する必要がある。という点です。
※コネクタうまい事使えばできなくもないですが。
Copilot Cowork
Cowork は、個人が複数工程の仕事を Copilot へ委任する実行環境です。
タスクはローカル上ではなく、クラウド上で処理されます。
Skills や Plugins によって、専門的な仕事の方法や Microsoft 365 外部サービスを再利用できます。
一方で、実行量に応じてコストが発生するため、利用者、用途、上限、予算、反復処理の標準化を管理する必要があります。
個人の AI 実行力を高める仕組みであり、チーム共同編集のためのプロジェクト管理基盤ではない点に注意が必要です。
Copilot Studio
Copilot Studio は、組織として継続利用するエージェントを、Power Platform 環境の、権限、ソリューション、ALM、公開、監視の仕組みの中で管理することが可能なサービスです。
複数人で保守する、業務品質へ影響する、異動・退職後も維持する、外部システムを操作するといったエージェントは、Copilot Studio で管理することが比較的適しています。
製品は機能数だけで比較せず、利用主体、所有、共有、更新、継続保守、コスト、ガバナンスの要件から選定する必要があります。

6. AI 資産は段階的に育て、組織標準へ昇格させる
すべての AI 活用を最初から全社標準として管理する必要はありません。
現場が自由に試せる余地を残さなければ、新しい使い方や価値ある業務改善は生まれにくいからです。
一方で、個人の試作を無秩序に許可・共有すると、所有者不在、重複、品質不明、セキュリティリスク、更新停止、コスト増加が起こってしまいます。
そのため、AI 資産を段階的に育てる必要があります。
レベル0:個人の試行
個人が Copilot Chat、単発のプロンプト、個人用 Agent Builder などを利用し、業務上の価値と課題を確認する。
レベル1:チーム共有
再利用可能な指示、テンプレート、Skill などとして整理し、限定的な範囲で共有する。
利用期間と所有者は明確にする。
レベル2:部門候補
複数人が継続利用し、業務品質やコストへ影響する場合、正式な評価対象とする。
所有者、保守担当者、評価基準、リスク、利用データ、公開範囲を定義する。
レベル3:全社標準
複数部門で再利用する資産は、Copilot Studio、管理対象 Plugin、正式ナレッジ、テストセット、RACI、ALM、監視を備えた組織資産として運用する。
昇格の判断では、次の観点を確認する。
- 明確な業務成果がある
- 他者や他業務で再利用できる
- 品質・安全性が評価されている
- 所有・更新・サポートを継続できる
- コストが価値に見合っている
- 異動・退職後も維持する必要がある
- 機密情報や外部システムを扱う
- 監査・説明責任がある
AI 資産の価値は、作成されたことではなく、再利用でき、保守でき、学習ループへ接続できることによって決まります。

7. 実践からナレッジを生み、次の仕事へ戻す
AI を実行して成果物を作っただけでは、その成果は組織としての能力にはなりません。
組織として学習を成立させるには、実行結果を記録し、評価し、学びを抽出し、次の業務へ再利用する必要があります。
学習ループは、次の流れで構成するとよいでしょう。
実行する
AI を活用して業務成果を作る。記録する
指示、利用情報、出力、人の修正、採用・不採用の判断を残す。振り返る
成功・失敗の原因、適用条件、例外、リスクを分析する。学ぶ
繰り返し利用できるパターン、判断基準、注意点を抽出する。評価する
人が事実、妥当性、品質、安全性、業務文脈を確認する。再利用する
ナレッジ、Skills、エージェント、業務フロー、教材へ反映する。
生成AI は、ログから論点を抽出し、情報を分類・要約し、過去の評価結果と照合し、ナレッジ候補を作る支援ができます。
しかし、文脈、妥当性、正式化、説明責任、更新・廃止の判断は、人が担う必要がある。
この循環では、「業務」、「AI 資産」、「ナレッジ」、「教育・人材」の4つのライフサイクルを接続します。
業務 → ログ → ナレッジ → AI資産 → 教育 → 次の業務
学習ループの目的は、ログを集めることではありません。
検証された知識を次の仕事、AI 資産、教育へ戻し、組織としての能力を継続的に高めることです。

8. セキュリティとガバナンスは継続的に更新する
ガバナンスは「導入前に一度行うチェック」として扱うのではなく、現在の利用状況と技術の高度化に応じて継続的に更新する必要があります。
導入フェーズで整備されるべきだった基盤
- SharePoint、Teams、OneDrive の権限
- 組織全体共有、共有リンク
- サイト、データ、AI 資産の所有者
- 異動・退職時の権限変更
- DLP、秘密度ラベル、保持・廃棄
- 監査ログ
- Connectors の管理
- エージェント作成・共有ポリシー
- 利用規程、管理責任者、ライセンス対象者
導入済みであっても、実施済みと仮定せず、技術アップデートや利用状況の変化に合わせて再点検する必要があります。
運用・定着化で継続すること
- 権限の定期点検
- Agent Builder、Skills、Plugins、Copilot Studio の棚卸し
- 所有者不在資産の検出と移管
- 共有範囲の見直し
- ナレッジ鮮度の確認
- AI 資産品質の評価
- 利用状況とコスト監視
- インシデント対応
- 教育内容の更新
- 不要資産の停止・廃止
高度化に伴い追加する統制
- Cowork や Copilot Studio の従量課金
- Plugins、外部 Connectors、外部 API
- Work IQ API / Work IQ MCP
- 外部モデルの利用
- 評価データ、トレース、フィードバック、メモリの評価
- 組織としての学習の知的財産管理
Microsoft 365 Copilot は、基本的に利用者が持つ既存の権限範囲で情報を利用します。
そのため、Copilot が新しい権限問題を作るわけでなく、以前から存在した過剰共有、放置サイト、古い権限を見えやすくする点を理解しておく必要があります。
これは管理者だけでなく、利用者全員が理解しておくべきことです。
安全な定着は、一度きりの導入チェックではなく、導入時、運用、高度化の3フェーズで統制を見直し続ける運用設計によってはじめて実現することができます。

9. 役割、評価、教育、コミュニティ、コストを一体で設計する
生成AI の価値を最大化するには、技術基盤だけでなく、人と組織の運用設計を整える必要があります。
役割と責任
AI CoE がすべてを抱えないよう、RACI チャートなどによって活動ごとの責任を明確にしましょう。
例)
- 経営:AI戦略、投資方針、リスク許容
- 業務責任者:業務成果、優先順位、最終的な業務責任
- AI資産オーナー:品質、所有、更新、廃止
- IT・セキュリティ:環境、権限、接続、監査
- 人事・L&D:役割、教育、評価、リスキリング
- ナレッジ責任者:正式化、鮮度、更新
- 作成者:設計、実装、テスト、改善
- コミュニティ・チャンピオン:現場の知見とフィードバックの循環
評価
評価は、次の4層を分けて測り、学習ループで接続するといいのではと考えています。
- AI 実行・AI 資産の品質
- 業務プロセスの成果
- 組織・事業成果
- 個人の人事評価
チャット回数、利用日数、トークン数(Copilot Credits 消費量)、エージェント実行回数を、個人の人事評価へ直接使ってはいけません。
利用量は価値を示さず、無駄な利用やコスト増加を誘発する可能性があるためです。
評価すべきなのは、成果物の品質、適切な AI 利用判断、出力の検証、リスク判断、再利用可能な改善、ナレッジ共有、他者支援、組織への波及です。
評価者はその点を理解したうえで、個人の活動や実績を評価する必要があると考えています。
ここは大きくはこれまでの評価基準と変わらないかと思います。
変わるとすると、情報の横展開や他者への支援がこれまで評価項目になかった場合は、新たに付け加えた方がよいのではないか。という点です。
教育
教育は、固定された機能教材と継続学習を分ける必要があると思います。
固定教材として維持するのは、生成AI の基礎、セキュリティ、責任分担、禁止事項、出力検証、主要製品の基本、申請・審査・廃止プロセスです。
これらは変化の激しい生成AI 領域においても比較的教材の更新が少ない要素であると思います。
新機能、モデル、Skills、Plugins、活用事例、失敗事例、AI PM 型の働き方、評価方法、コスト最適化は、技術アップデート、社内コミュニティや実務の状況を通じて継続的に更新する必要があります。
これらは一度学んで終わりではない要素であるので、継続的な学習方法の確立と、教材のアップデート方法の確立が求められます。
コミュニティ
社内コミュニティは単なる交流会の場で終わらせてはいけません。
成功、失敗、疑問、改善案、新機能、再利用可能な AI 資産、組織としての生成AI 活用の評価結果、現場課題を、現場と AI CoE の間で循環させる組織学習のインフラとして構築していく必要があります。
コスト
コストは、固定ライセンス、従量費、運用費へ分ける必要があります。
目的は利用を抑制することではなく、高価値業務へ予算を配分し、反復性の高い処理を標準化し、品質、再利用性、コストを同時に最適化することです。
技術、役割、評価、教育、コミュニティ、コストが連動して初めて、生成AI の力は組織能力として定着していきます。

10. 小さく始め、学びながら継続的に拡大する
生成AI の全社活用を、最初から完成した全社基盤として設計することは現実的ではありません。
製品、モデル、利用方法、課金、リスクは変化し続けるため、組織自身が学びながら管理モデルを更新する必要があります。
フェーズ1:準備・小さく始める
- 現在の利用状況、権限、AI 資産、コストを把握する
- 全社原則とリスク分類を定義する
- 小規模な業務や小規模なチームで試行する
- 成果と失敗を記録する
フェーズ2:試行・評価
- 業務成果と AI 資産の品質を評価する
- 所有者、評価基準、更新方法を設定する
- 再利用可能なプロンプト、テンプレート、ナレッジを整理する
- 特定のチームや部門へ限定的に展開する
フェーズ3:標準化・拡大
- 反復性が高く、複数人が利用する業務を標準化する
- RACI、ALM、監視、教育体制を整備する
- 部門間で再利用する
フェーズ4:全社展開・最適化
- 評価、改善、教育、コミュニティが自走できるようにする
- AI 資産の棚卸しと廃止による、資産の最新化を定常化する
- 品質、リスク、コストを継続的に最適化する
- モデルや製品が変わっても学習資産が残るように設計にする
意思決定者が確認すべきなのは、単に何のサービス導入するかだけではありません。
- AI へ任せる仕事と、人が責任を持つ判断は何か
- どの業務を再設計するのか
- 何を組織固有の知識・判断軸として残すのか
- どの AI 資産を個人利用から組織標準へ昇格するのか
- 品質、コスト、リスクをどう評価するのか
- 学びを次の業務へ戻す仕組みがあるか
- AI 活用が一部の人材へ依存せず、組織能力になっているか
生成AI 活用の成否は、ライセンス数や利用回数では決まりません。
人と AI の役割を再設計し、AI 資産を所有・評価・更新し、現場と CoE の学習ループを接続し、コスト・リスク・価値を同時に管理できるかによって決まります。
AI を導入した組織ではなく、AI を前提として学習し続ける組織こそが、生成AI 時代の競争力を持つと考えています。

まとめ
生成AI時代の組織設計では、次の10点が重要になると考えています。
- 生成AI 導入を、ツール導入ではなく組織学習システムの構築として捉える
- 人の能力と AI 資産を相互に強化する
- 個人の役割を、実行から委任・評価・統合へ広げる
- AI CoE と現場によるフェデレーテッド型組織を構築する
- Microsoft 365 Copilot エコシステムを管理モデルで使い分ける
- AI 資産を個人の試行から組織標準へ段階的に昇格させる
- 実行結果をナレッジ、AI資産、教育へ戻す学習ループを持つ
- セキュリティとガバナンスを継続的に更新する
- 役割、評価、教育、コミュニティ、コストを一体で設計する
- 小さく始め、評価・改善しながら組織能力として拡大する
生成AI は、単に人の作業を代替する技術ではありません。
人と AI が共に学び、その学びを再利用可能な組織資産へ変えるための技術であると私は捉えています。
組織がその循環を設計できるかどうかが、今後の競争力を左右すると思います。
おわりに
以上がざっくり?私の生成AI 時代における 個人/組織 としての働き方要点です。
働き方といっても機能の使い方ではなく概念的なところの考えですので難しいですね。。。
冒頭でも述べたように、考えが甘いところや突っ込みどころなど満載など思いますので、皆さまの意見も是非伺いたいです。
皆さまのコメントお待ちしております。